编写各大搜索引擎的URL采集模块(baidu、bing、google)
前言
前段时间编写了几个URL采集模块,在这里小结一下,总体来说都是利用爬虫的原理,采集各大搜索引擎的url,主要是这些规则,可能会随着时间改变而改变
URL采集器模块
baidu采集模块
由于三个模块基本相同,而百度采集到的URL地址需要进行一个302的跳转,所以这里以百度模块来展开。
准备工作
# 默认采集前10页可以在下面更改
PAGES = 10
import requests
from lxml import etree
from urllib.parse import quote, urlparse
from concurrent.futures import ThreadPoolExecutor开始编写采集模块
def BaiduScan(keywords):
result = set()
for i in range(0, PAGES*10, 10):
url = 'https://www.baidu.com/s?wd={}&pn={}'.format(quote(keywords), i)
print("正在采集第{}页,请耐心等待".format(int(i/10+1)))
try:
HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': 'BAIDUID=832CF61CDAEF34C68E7CA06F591DF82A:FG=1; BIDUPSID=832CF61CDAEF34C68E7CA06F591DF82A; PSTM=1544962484; BD_UPN=12314753; BDUSS=RWclRJUURtR25qZWxKZWZiN0JuSlJVTWpKRjhvb3ROdmIyNnB0eEwwY2FVOWxjSVFBQUFBJCQAAAAAAAAAAAEAAADS9fNj0-~PxM600esAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABrGsVwaxrFcck; cflag=13%3A3; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BD_HOME=1; delPer=0; BDRCVFR[feWj1Vr5u3D]=mk3SLVN4HKm; H_PS_PSSID=1453_21088_20692_28774_28720_28558_28832_28584; B64_BOT=1; BD_CK_SAM=1; PSINO=1; sug=3; sugstore=1; ORIGIN=2; bdime=0; H_PS_645EC=87ecpN5CzJjR5UwprsIowJPhqh6m9t1xGvxRkjeNmvcXBhI86ytKIjXLMhQ',
'Host': 'www.baidu.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36',
}
HEADERS2 = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36',
}
re = requests.get(url, headers=HEADERS, timeout=20)
text = re.content.decode('utf-8')
tree = etree.HTML(text)
# 利用xpath
divs = tree.xpath("//div[@id='content_left']/div")
for div in divs:
urls = div.xpath(".//h3/a/@href")
# print(urls)
for url in urls:
r = requests.get(url=url, headers=HEADERS2, timeout=20)
if r.status_code == 200 or r.status_code == 302:
u = urlparse(r.url)
ur = u.scheme + '://' + u.netloc + u.path
print(ur)
result.add(ur)
except Exception as e:
pass
if result != {}:
for ur in result:
with open('baidu_url_result.txt', 'a+', encoding='utf-8')as a:
a.write(ur + '\n')
print('搜索完成,已经保存到:"baidu_url_result.txt"')参数说明:
1、url规则编写:
url = 'https://www.baidu.com/s?wd={}&pn={}'.format(quote(keywords), i)url的地址是根据百度url规则来编写的
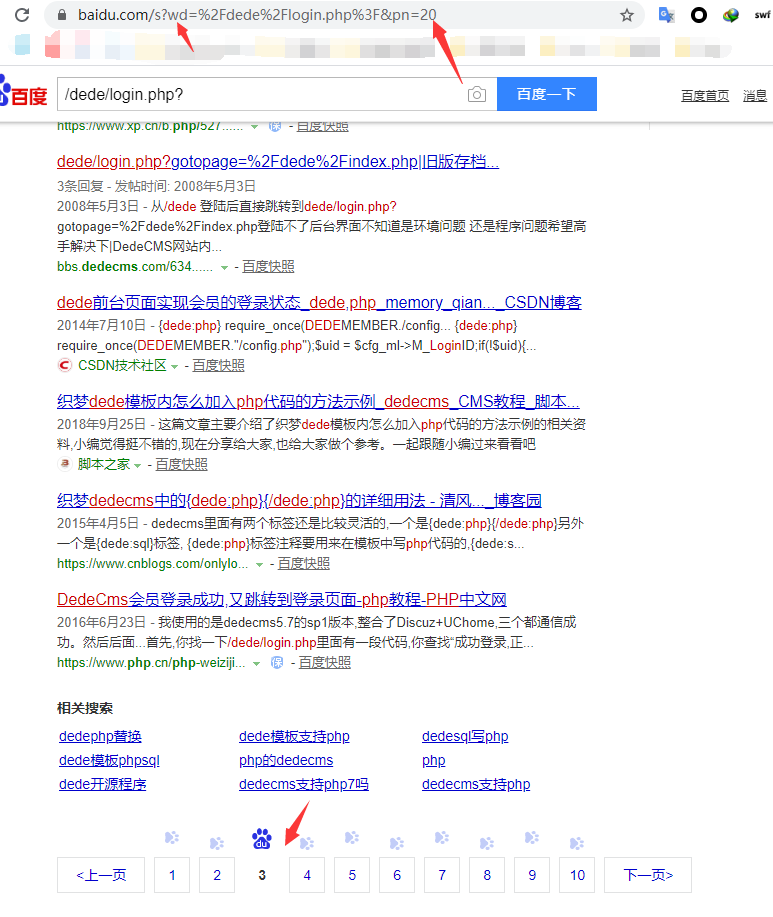
通过简单的观察我们可以发现,wd就是我们要进行搜索的关键字,而pn代表的是页数(0,代表第一页,10代表第二页,20代表第三页以此类推)
写一个”for i in range(0, PAGES*10, 10):”在range中以10为步长从0,PAGES 10 这样的话url的规则就编写完成了。
2、xpath的规则编写:
这里我用xpath来采集URL在前面都是正常的request请求。
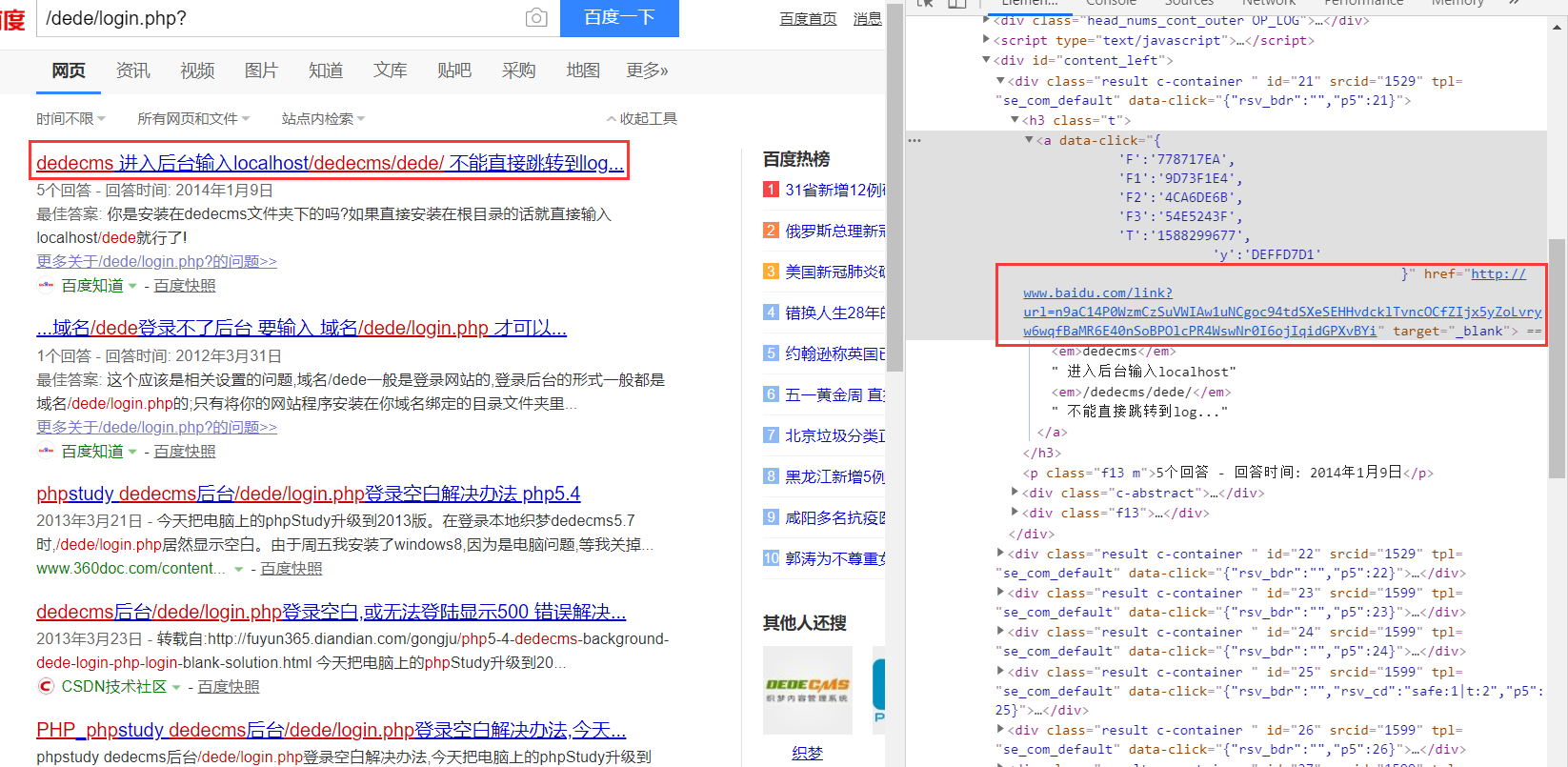
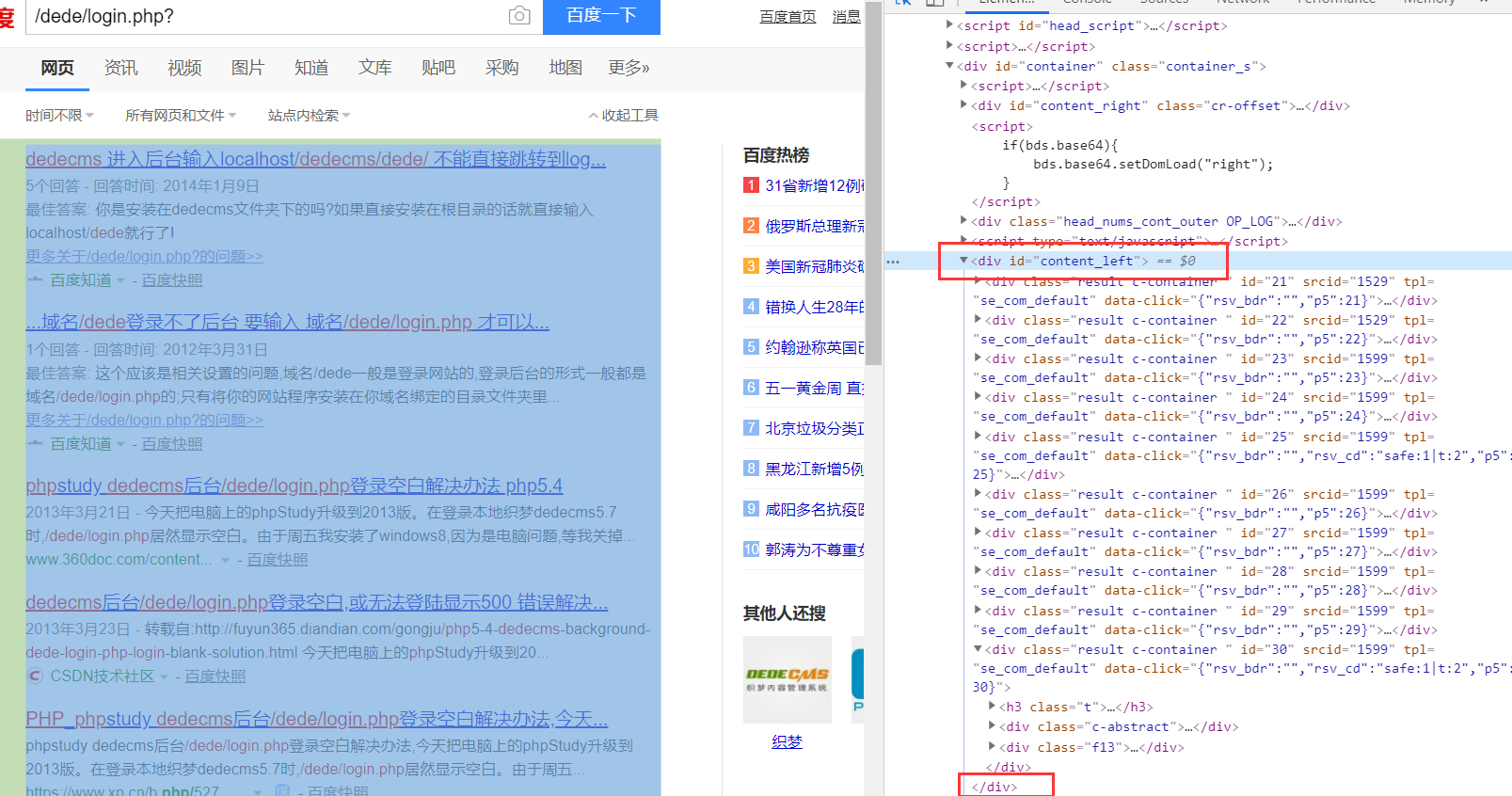
通过观察我们可以发现需要的数据在标红色里面,而所有的数据又在div标签并且id=’content_left’中,在得到这些数据中,我们对divs进行遍历”.//h3/a/@href”
到这里xpath的规则就编写完成了,你可以获得一个百度跳转到其他网页的列表,下面再对这些URL进行处理
3、302跳转处理:
在上面获取了跳转前的链接,并不是我们需要的地址,所以还需要进一步处理
在进行request请求之后使用urlparse()函数获得类似下面这样的数据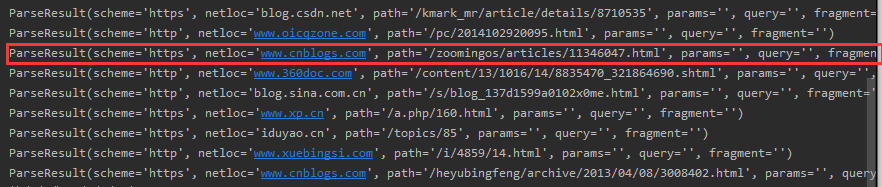
ur = u.scheme + '://' + u.netloc + u.path最后把这些组合起来就可以了
4、编写main()
if __name__ == '__main__':
inp1 = input("请选择搜索模式:\n 1 :批量从文件关键字搜索\n 2 :输入一个关键字进行搜索\n")
if inp1 == '1':
inp = input('导入标题文本:')
titles = list(set([x.strip() for x in open(inp, 'r', encoding='utf-8').readlines()]))
print('目标总数:{}'.format(len(titles)))
with ThreadPoolExecutor(10) as p:
# 开 10 个线程池
res = [p.submit(BaiduScan, url) for url in titles]
elif inp1 == '2':
url = input('输入keywords\n')
BaiduScan(url)
else:
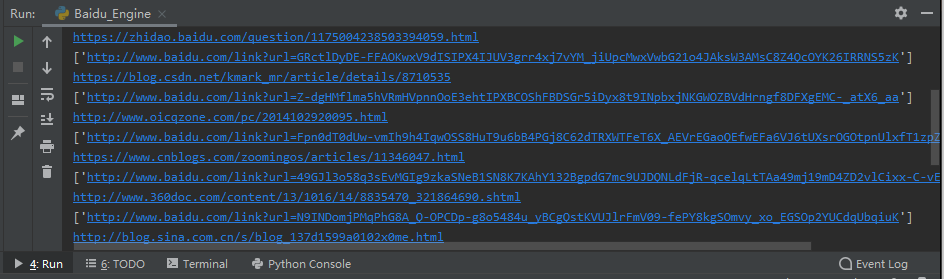
pass使用效果:
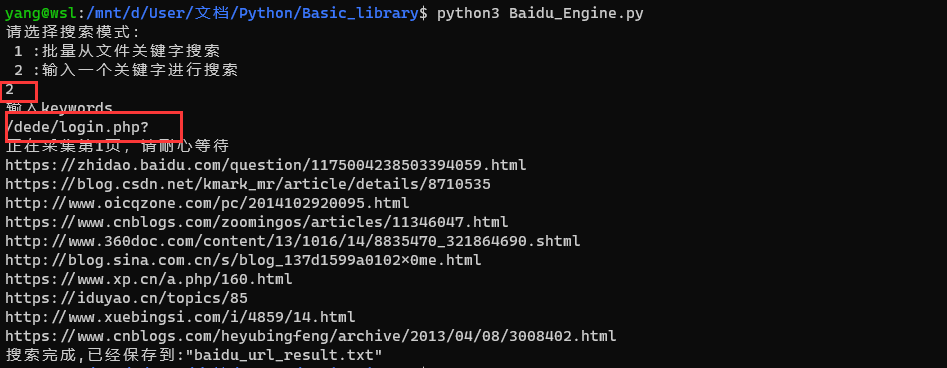
bing采集模块
bing和baidu大同小异,所以这里就不赘述,所以这里附上URL和xpath规则
# URL规则
url = 'https://cn.bing.com/search?q={}&first={}'.format(quote(keywords), i)
# xpath规则
divs = tree.xpath("//ol[@id='b_results']/li")
for div in divs:
url = div.xpath(".//h2/a/@href")
print(url[0])
result.add(url[0])使用效果:
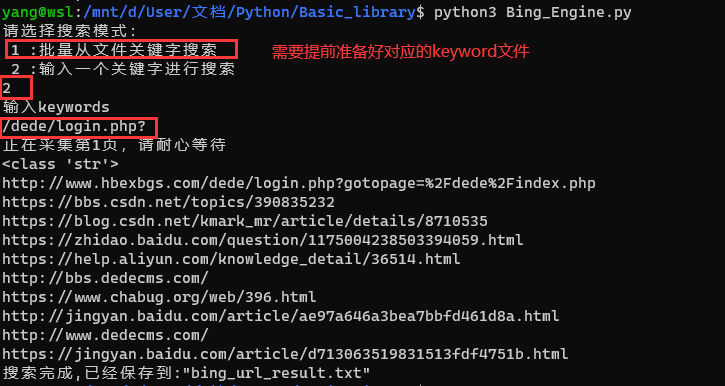
google采集模块
同样的google和bing、baidu也是大同小异,不同的是google需要能够科学上网的网络,同时google的“确定你不是机器人”,可能需要进一步的绕过
# URL规则
url = 'https://www.google.com/search?q={}&start={}'.format(quote(keywords), i)
# xptah规则
divs = tree.xpath("//div[@class='g']")
for div in divs:
url = div.xpath(".//div[@class='r']/a/@href")
print(url[0])
result.add(url[0])
# socket代理示例
proxies = {"http": "socks5://127.0.0.1:10808", "https": "socks5://127.0.0.1:10808", }使用效果:
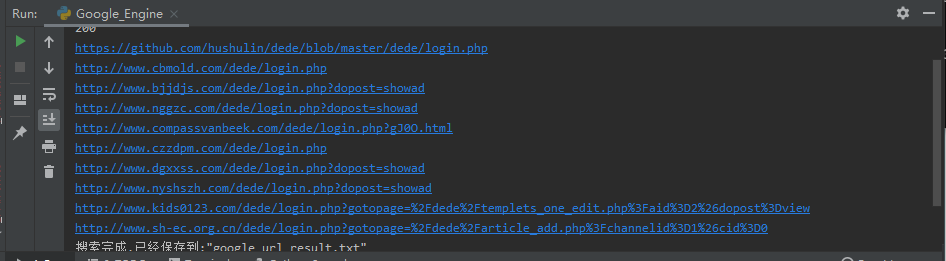
声明:
- 笔者初衷用于分享与交流网络知识,若读者因此作出任何危害网络安全行为后果自负,与作者无关!